go常见问题:
1. go关键字有那些?
下面列举了 Go 代码中会使用到的 25 个关键字或保留字:
| break | default | func | interface | select |
|---|---|---|---|---|
| case | defer | go | map | struct |
| chan | else | goto | package | switch |
| const | fallthrough | if | range | type |
| continue | for | import | return | var |
除了以上介绍的这些关键字,Go 语言还有 36 个预定义标识符:
| append | bool | byte | cap | close | complex | complex64 | complex128 | uint16 |
|---|---|---|---|---|---|---|---|---|
| copy | false | float32 | float64 | imag | int | int8 | int16 | uint32 |
| int32 | int64 | iota | len | make | new | nil | panic | uint64 |
| println | real | recover | string | true | uint | uint8 | uintptr |
程序一般由关键字、常量、变量、运算符、类型和函数组成。
程序中可能会使用到这些分隔符:括号 (),中括号 [] 和大括号 {}。
程序中可能会使用到这些标点符号:.、,、;、: 和 …。
2. new函数和make函数的区别?
func new(Type) *Typenew的内置函数分配内存。第一个参数是一个类型,而不是一个值,返回的值是指向该类型新分配的零值的指针。
func make(t Type, size ...IntegerType) Typemake内置函数分配并初始化类型为slice、map或channel(仅限)的对象。与new一样,第一个参数是类型,而不是值。与new不同,make的返回类型与其参数的类型相同,而不是指向它的指针。结果的规格取决于类型:
slice(切片):size指定长度。切片的容量是等于它的长度。第二个整数参数可以提供给指定不同的容量;它不能小于长例如,make([]int,0,10)分配一个底层数组大小为10,并返回长度为0、容量为10的切片由这个底层数组支持。
map(键对):一张空地图被分配了足够的空间来存放地图指定的元素数。在这种情况下,尺寸可以省略分配了一个小的起始大小。
channel(通道):size通道的缓冲区用指定的缓冲容量。如果为零,或省略了大小,则通道为没有缓冲。
就是说make函数只能用于创建slice、map和channel,而new函数可以创建多种类型
3. 数组和切片有什么区别?
Go语言中数组是固定长度的,不能动态扩容,在编译期就会确定大小,声明方式如下:
var buffer [255]int
buffer := [255]int{0}切片是对数组的抽象,因为数组的长度是不可变的,在某些场景下使用起来就不是很方便,所以Go语言提供了一种灵活,功能强悍的内置类型切片(“动态数组”),与数组相比切片的长度是不固定的,可以追加元素。切片是一种数据结构,切片不是数组,切片描述的是一块数组。
我们可以直接声明一个未指定大小的数组来定义切片,也可以使用make()函数来创建切片,声明方式如下:
var slice []int // 直接声明
slice := []int{1,2,3,4,5} // 字面量方式
slice := make([]int, 5, 10) // make创建
slice := array[1:5] // 截取下标的方式
slice := *new([]int) // new一个切片可以使用append追加元素,当cap不足时进行动态扩容。
切片扩容策略:
newcap := old.cap
// 两倍扩容
doublecap := newcap + newcap
// 新切片需要的容量大于两倍扩容的容量,则直接按照新切片需要的容量扩容
if cap > doublecap {
newcap = cap
} else {
// 原 slice 容量小于 1024 的时候,新 slice 容量按2倍扩容
if old.cap < 1024 {
newcap = doublecap
} else { // 原 slice 容量超过 1024,新 slice 容量变成原来的1.25倍。
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}切片在扩容时会进行内存对齐,这个和内存分配策略相关。
进行内存对齐之后,新 slice 的容量是要 大于等于老 slice 容量的 2倍或者1.25倍,则直接按照新切片需要的容量扩容;
当原 slice 容量小于 1024 的时候,新 slice 容量变成原来的 2 倍;
原 slice 容量超过 1024,新 slice 容量变成原来的1.25倍。
-新容量=所需的容量- > 2倍原容量 > -新容量=2倍原容量- > 1024 > -新容量=1/4倍原容量- 3.1 切片的拷贝:
深浅拷贝都是进行复制,区别在于复制出来的新对象与原来的对象在它们发生改变时,是否会相互影响,本质区别就是复制出来的对象与原对象是否会指向同一个地址。在Go语言,切片拷贝有三种方式:
- 使用=操作符拷贝切片,这种就是浅拷贝
- 使用[:]下标的方式复制切片,这种也是浅拷贝
- 使用Go语言的内置函数copy()进行切片拷贝,这种就是深拷贝
func copy(dst []Type, src []Type) intcopy内置函数将元素从源切片复制到目标切片。(作为特例,它还将把字符串中的字节复制到字节片中。)源和目标可能重叠。Copy返回复制的元素数,即 len(src)和 len(dst)的最小值。
3.2 零切片、空切片、nil切片是什么?
为什么问题中这么多种切片呢?因为在Go语言中切片的创建方式有五种,不同方式创建出来的切片也不一样;
- 零切片
我们把切片内部数组的元素都是零值或者底层数组的内容就全是 nil的切片叫做零切片,使用make创建的、长度、容量都不为0的切片就是零值切片:
slice := make([]int,5) // 0 0 0 0 0
slice := make([]*int,5) // nil nil nil nil nil- nil切片
nil切片的长度和容量都为0,并且和nil比较的结果为true,采用直接创建切片的方式、new创建切片的方式都可以创建nil切片:
var slice []int
s = append(s, 1)//允许对值为 nil 的 slice 添加元素
var slice = *new([]int)- 空切片
空切片的长度和容量也都为0,但是和nil的比较结果为false,因为所有的空切片的数据指针都指向同一个地址 0xc42003bda0;使用字面量、make可以创建空切片:
var slice = []int{}
var slice = make([]int, 0)空切片指向的 zerobase 内存地址是一个神奇的地址,从 Go 语言的源代码中可以看到它的定义:
// base address for all 0-byte allocations
var zerobase uintptr
// 分配对象内存
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
if size == 0 {
return unsafe.Pointer(&zerobase)
}
...
}Go语言提供了range关键字用于for 循环中迭代数组(array)、切片(slice)、通道(channel)或集合(map)的元素,有两种使用方式:
for k,v := range slice { }
for k := range slice { }第一种是遍历下标和对应值,第二种是只遍历下标,使用range遍历切片时会先拷贝一份,然后在遍历拷贝数据
因为变量v是拷贝切片中的数据,所以修改v不会对原切片有影响。
4. range 迭代 map是有序的吗?
/* 声明变量,默认 map 是 nil */
var map_variable map[key_data_type]value_data_type
/* 使用 make 函数 ,如果不初始化 map,那么就会创建一个 nil map。nil map 不能用来存放键值对*/
map_variable := make(map[key_data_type]value_data_type)
/* range 迭代 map */
for k,v range map_variable {
fmt.Printf("map`s key=%s,map`s value=%s",k,v)
}Map 是一种无序的键值对的集合。Map 最重要的一点是通过 key 来快速检索数据,key 类似于索引,指向数据的值。
Map 是一种集合,所以我们可以像迭代数组和切片那样迭代它。不过,Map 是无序的,我们无法决定它的返回顺序,这是因为 Map 是使用 hash 表来实现的。
一致方法:将map的key存入一有序数组中,然后遍历数组key值,依次取出map的value值
5. go循环中switch语句和select语句的区别及for语句?
5.1 switch语句
switch 语句用于基于不同条件执行不同动作,每一个 case 分支都是唯一的,从上至下逐一测试,直到匹配为止。
switch 语句执行的过程从上至下,直到找到匹配项,匹配项后面也不需要再加 break。
switch 默认情况下 case 最后自带 break 语句,匹配成功后就不会执行其他 case,如果我们需要执行后面的 case,可以使用 fallthrough 。
switch val {
case val1:
...//自带 break 语句,匹配成功后就不会执行其他 case,直接返回
case val2:
...//如果我们需要执行后面的 case,可以使用fallthrough
default:
...
}5.2 select语句
select 是 Go 中的一个控制结构,类似于用于通信的 switch 语句。每个 case 必须是一个通信操作,要么是发送要么是接收。所以常用于goroutine的完美退出。
select 随机执行一个可运行的 case。如果没有 case 可运行,它将阻塞,直到有 case 可运行。一个默认的子句应该总是可运行的。
select {
case communication clause :
statement(s);
case communication clause :
statement(s);
/* 你可以定义任意数量的 case */
default : /* 可选 */
statement(s);
}以下描述了 select 语句的语法:
每个 case 都必须是一个通信
所有 channel 表达式都会被求值
所有被发送的表达式都会被求值
如果任意某个通信可以进行,它就执行,其他被忽略。
如果有多个 case 都可以运行,Select 会随机公平地选出一个执行。其他不会执行。
否则:
- 如果有 default 子句,则执行该语句。
- 如果没有 default 子句,select 将阻塞,直到某个通信可以运行;Go 不会重新对 channel 或值进行求值。
5.3 for语句
for 循环支持 continue 和 break 来控制循环,但是它提供了一个更高级的break,可以选择中断哪一个循环 for 循环不支持以逗号为间隔的多个赋值语句,必须使用平行赋值的方式来初始化多个变量。
6. 如何从 panic 中恢复?
在一个 defer 延迟执行的函数中调用 recover ,它便能捕捉/中断 panic。
// 错误的 recover 调用示例
func main() {
recover() // 什么都不会捕捉
panic("not good") // 发生 panic,主程序退出
recover() // 不会被执行
println("ok")
}
// 正确的 recover 调用示例
func main() {
defer func() {
fmt.Println("recovered: ", recover())
}()
panic("not good")
}recover 必须在 defer 函数中运行。recover 捕获的是祖父级调用时的异常,直接调用时无效。
7. 闭包错误引用同一个变量问题怎么处理?
在每轮迭代中生成一个局部变量 i 。如果没有 i := i 这行,将会打印同一个变量。
func main() {
for i := 0; i < 5; i++ {
i := i
defer func() {
println(i)
}()
}
}或者是通过函数参数传入 i 。
func main() {
for i := 0; i < 5; i++ {
defer func(i int) {
println(i)
}(i)
}
}8. go语言触发异常的场景有哪些?
- 空指针解析
- 下标越界
- 除数为0
- 调用 panic 函数
9. Go的Struct能不能比较?
- 相同struct类型的可以比较
- 不同struct类型的不可以比较,编译都不过,类型不匹配
10. 协程和线程和进程的区别?
并发掌握,goroutine和channel声明与使用!
进程: 进程是具有一定独立功能的程序,进程是系统资源分配和调度的最小单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。
线程: 线程是进程的一个实体,线程是内核态,而且是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
协程: 协程是一种用户态的轻量级线程,协程的调度完全是由用户来控制的。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
10.1 Goroutine和线程的区别?
- 一个线程可以有多个协程
- 线程、进程都是同步机制,而协程是异步
- 协程可以保留上一次调用时的状态,当过程重入时,相当于进入了上一次的调用状态
- 协程是需要线程来承载运行的,所以协程并不能取代线程,「线程是被分割的CPU资源,协程是组织好的代码流程」
重点:
1. 垃圾回收(gabage collection(简称GC))
垃圾回收、三色标记原理
垃圾回收就是对程序中不再使用的内存资源进行自动回收的操作。
1.1 常见的垃圾回收算法:
- 引用计数:每个对象维护一个引用计数,当被引用对象被创建或被赋值给其他对象时引用计数自动加 +1;如果这个对象被销毁,则计数 -1 ,当计数为 0 时,回收该对象。
- 优点:对象可以很快被回收,不会出现内存耗尽或到达阀值才回收。
- 缺点:不能很好的处理循环引用
- 标记-清除(go使用):从根变量开始遍历所有引用的对象,引用的对象标记“被引用”,没有被标记的则进行回收。
- 优点:解决了引用计数的缺点。
- 缺点:需要 STW(stop the world),暂时停止程序运行。
- 分代收集(java使用):按照对象生命周期长短划分不同的代空间,生命周期长的放入老年代,短的放入新生代,不同代有不同的回收算法和回收频率。
- 优点:回收性能好
- 缺点:算法复杂
1.2 三色标记法(即标记-清除算法)
- 初始状态下所有对象都是白色的。
- 从根节点开始遍历所有对象,把遍历到的对象变成灰色对象
- 遍历灰色对象,将灰色对象引用的对象也变成灰色对象,然后将遍历过的灰色对象变成黑色对象。
- 循环步骤3,直到灰色对象全部变黑色。
- 通过写屏障(write-barrier)检测对象有变化,重复以上操作
- 收集所有白色对象(垃圾)。
- 通常小对象过多会导致GC三色法消耗过多的GPU。优化思路是,减少对象分配。
1.3 STW(Stop The World)
- 为了避免在 GC 的过程中,对象之间的引用关系发生新的变更,使得GC的结果发生错误(如GC过程中新增了一个引用,但是由于未扫描到该引用导致将被引用的对象清除了),停止所有正在运行的协程。
- STW对性能有一些影响,Golang目前已经可以做到1ms以下的STW。
1.4 写屏障(Write Barrier)
- 为了避免GC的过程中新修改的引用关系到GC的结果发生错误,我们需要进行STW。但是STW会影响程序的性能,所以我们要通过写屏障技术尽可能地缩短STW的时间。
造成引用对象丢失的条件:
一个黑色的节点A新增了指向白色节点C的引用,并且白色节点C没有除了A之外的其他灰色节点的引用,或者存在但是在GC过程中被删除了。以上两个条件需要同时满足:满足条件1时说明节点A已扫描完毕,A指向C的引用无法再被扫描到;满足条件2时说明白色节点C无其他灰色节点的引用了,即扫描结束后会被忽略 。
写屏障破坏两个条件其一即可
- 破坏条件1:Dijistra写屏障
满足强三色不变性:黑色节点不允许引用白色节点 当黑色节点新增了白色节点的引用时,将对应的白色节点改为灰色
- 破坏条件2:Yuasa写屏障
满足弱三色不变性:黑色节点允许引用白色节点,但是该白色节点有其他灰色节点间接的引用(确保不会被遗漏) 当白色节点被删除了一个引用时,悲观地认为它一定会被一个黑色节点新增引用,所以将它置为灰色
1.5 GC 的触发条件?
主动触发(手动触发),通过调用 runtime.GC 来触发GC,此调用阻塞式地等待当前GC运行完毕。
被动触发,分为两种方式:
- 使用步调(Pacing)算法,其核心思想是控制内存增长的比例,每次内存分配时检查当前内存分配量是否已达到阈值(环境变量GOGC):默认100%,即当内存扩大一倍时启用GC。
- 使用系统监控,当超过两分钟没有产生任何GC时,强制触发 GC。
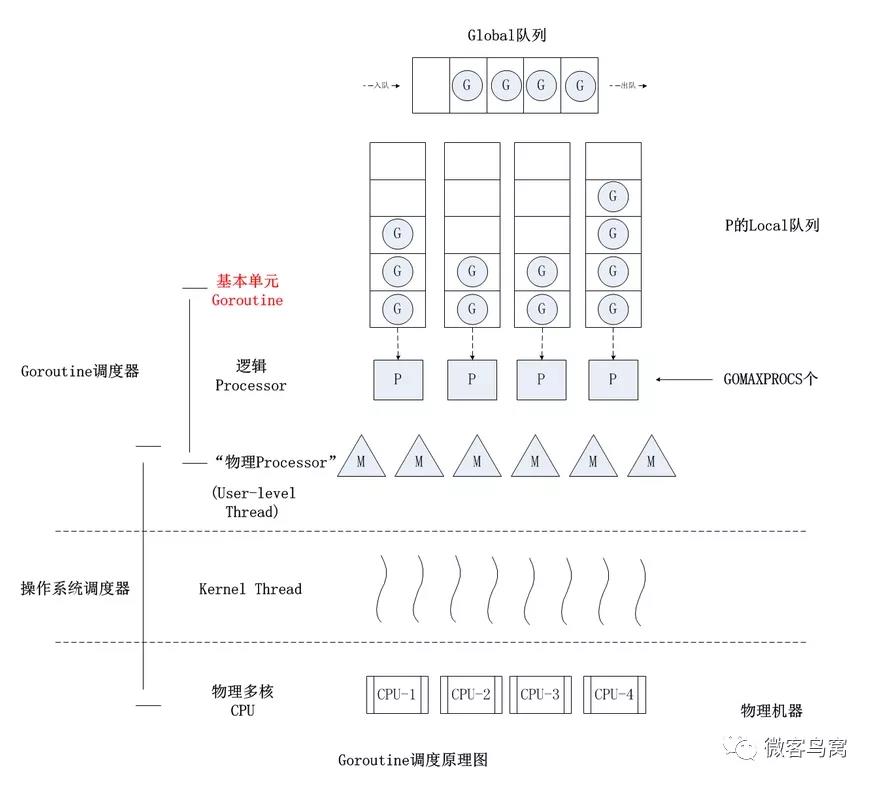
2. GPM 调度 和 CSP 模型
协程的深入剖析
2.1 CSP 模型?
CSP 模型是“以通信的方式来共享内存”,不同于传统的多线程通过共享内存来通信。用于描述两个独立的并发实体通过共享的通讯 channel (管道)进行通信的并发模型。
2.2 GPM 分别是什么、分别有多少数量?
- G(Goroutine):即Go协程,每个go关键字都会创建一个协程。
- M(Machine):工作线程,在Go中称为Machine,数量对应真实的CPU数(真正干活的对象)。
- P(Processor):处理器(Go中定义的一个摡念,非CPU),包含运行Go代码的必要资源,用来调度 G 和 M 之间的关联关系,其数量可通过 GOMAXPROCS() 来设置,默认为核心数。
M必须拥有P才可以执行G中的代码,P含有一个包含多个G的队列,P可以调度G交由M执行。
2.3 Goroutine调度策略
- 队列轮转:P 会周期性的将G调度到M中执行,执行一段时间后,保存上下文,将G放到队列尾部,然后从队列中再取出一个G进行调度。除此之外,P还会周期性的查看全局队列是否有G等待调度到M中执行。
- 系统调用:当G0即将进入系统调用时,M0将释放P,进而某个空闲的M1获取P,继续执行P队列中剩下的G。M1的来源有可能是M的缓存池,也可能是新建的。
- 当G0系统调用结束后,如果有空闲的P,则获取一个P,继续执行G0。如果没有,则将G0放入全局队列,等待被其他的P调度。然后M0将进入缓存池睡眠。
3. CHAN 原理
3.1 结构体
type hchan struct {
qcount uint // 队列中的总元素个数
dataqsiz uint // 环形队列大小,即可存放元素的个数
buf unsafe.Pointer // 环形队列指针
elemsize uint16 //每个元素的大小
closed uint32 //标识关闭状态
elemtype *_type // 元素类型
sendx uint // 发送索引,元素写入时存放到队列中的位置
recvx uint // 接收索引,元素从队列的该位置读出
recvq waitq // 等待读消息的goroutine队列
sendq waitq // 等待写消息的goroutine队列
lock mutex //互斥锁,chan不允许并发读写
}3.2 读写流程
向 channel 写数据:
若等待接收队列 recvq 不为空,则缓冲区中无数据或无缓冲区,将直接从 recvq 取出 G ,并把数据写入,最后把该 G 唤醒,结束发送过程。
若缓冲区中有空余位置,则将数据写入缓冲区,结束发送过程。
若缓冲区中没有空余位置,则将发送数据写入 G,将当前 G 加入 sendq ,进入睡眠,等待被读 goroutine 唤醒。
从 channel 读数据
若等待发送队列 sendq 不为空,且没有缓冲区,直接从 sendq 中取出 G ,把 G 中数据读出,最后把 G 唤醒,结束读取过程。
如果等待发送队列 sendq 不为空,说明缓冲区已满,从缓冲区中首部读出数据,把 G 中数据写入缓冲区尾部,把 G 唤醒,结束读取过程。
如果缓冲区中有数据,则从缓冲区取出数据,结束读取过程。
将当前 goroutine 加入 recvq ,进入睡眠,等待被写 goroutine 唤醒。
关闭 channel
1.关闭 channel 时会将 recvq 中的 G 全部唤醒,本该写入 G 的数据位置为 nil。将 sendq 中的 G 全部唤醒,但是这些 G 会 panic。
panic 出现的场景还有:
关闭值为 nil 的 channel
关闭已经关闭的 channel
向已经关闭的 channel 中写数据
3.2 无缓冲 Chan 的发送和接收是否同步?
// 无缓冲的channel由于没有缓冲发送和接收需要同步
ch := make(chan int)
//有缓冲channel不要求发送和接收操作同步
ch := make(chan int, 2) channel 无缓冲时,发送阻塞直到数据被接收,接收阻塞直到读到数据;channel有缓冲时,当缓冲满时发送阻塞,当缓冲空时接收阻塞。
3.3 线程安全
Channel 可以理解是一个先进先出的队列,通过管道进行通信,发送一个数据到Channel和从Channel接收一个数据都是原子性的。不要通过共享内存来通信,而是通过通信来共享内存,前者就是传统的加锁,后者就是Channel。设计Channel的主要目的就是在多任务间传递数据的,本身就是安全的。
3.4 异步
Channel是异步进行的, channel存在3种状态:
- nil,未初始化的状态,只进行了声明,或者手动赋值为nil
- active,正常的channel,可读或者可写
- closed,已关闭,千万不要误认为关闭channel后,channel的值是nil
| 操作 | 一个零值nil通道 | 一个非零值但已关闭的通道 | 一个非零值且尚未关闭的通道 |
|---|---|---|---|
| 关闭 | 产生恐慌 | 产生恐慌 | 成功关闭 |
| 发送数据 | 永久阻塞 | 产生恐慌 | 阻塞或者成功发送 |
| 接收数据 | 永久阻塞 | 永不阻塞 | 阻塞或者成功接收 |
4. context 结构原理
4.1 用途
Context(上下文)是Golang应用开发常用的并发控制技术 ,它可以控制一组呈树状结构的goroutine,每个goroutine拥有相同的上下文。Context 是并发安全的,主要是用于控制多个协程之间的协作、取消操作。
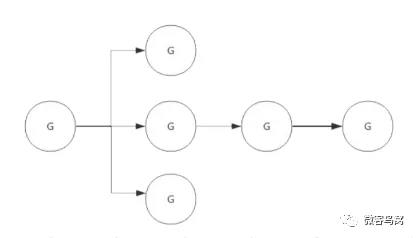
4.2 数据结构
Context 只定义了接口,凡是实现该接口的类都可称为是一种 context。
并发控制神器之Context
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}- 「Deadline」 方法:可以获取设置的截止时间,返回值 deadline 是截止时间,到了这个时间,Context 会自动发起取消请求,返回值 ok 表示是否设置了截止时间。
- 「Done」 方法:返回一个只读的 channel ,类型为 struct{}。如果这个 chan 可以读取,说明已经发出了取消信号,可以做清理操作,然后退出协程,释放资源。
- 「Err」 方法:返回Context 被取消的原因。
- 「Value」 方法:获取 Context 上绑定的值,是一个键值对,通过 key 来获取对应的值。
5. 竞态、内存逃逸
并发控制,同步原语 sync 包
5.1 竞态
资源竞争,就是在程序中,同一块内存同时被多个 goroutine 访问。我们使用 go build、go run、go test 命令时,添加 -race 标识可以检查代码中是否存在资源竞争。
解决这个问题,我们可以给资源进行加锁,让其在同一时刻只能被一个协程来操作。
- sync.Mutex
- sync.RWMutex
5.2 逃逸分析
面试官问我go逃逸场景有哪些,我???
「逃逸分析」就是程序运行时内存的分配位置(栈或堆),是由编译器来确定的。堆适合不可预知大小的内存分配。但是为此付出的代价是分配速度较慢,而且会形成内存碎片。
逃逸场景:
- 指针逃逸
- 栈空间不足逃逸
- 动态类型逃逸
- 闭包引用对象逃逸
具体内容看下一篇文章

